

Al igual que me pasó con los contenidos del lunes, llego vía Hacker News a otro texto bastante curioso, A Neural Parametric Singing Synthesizer:
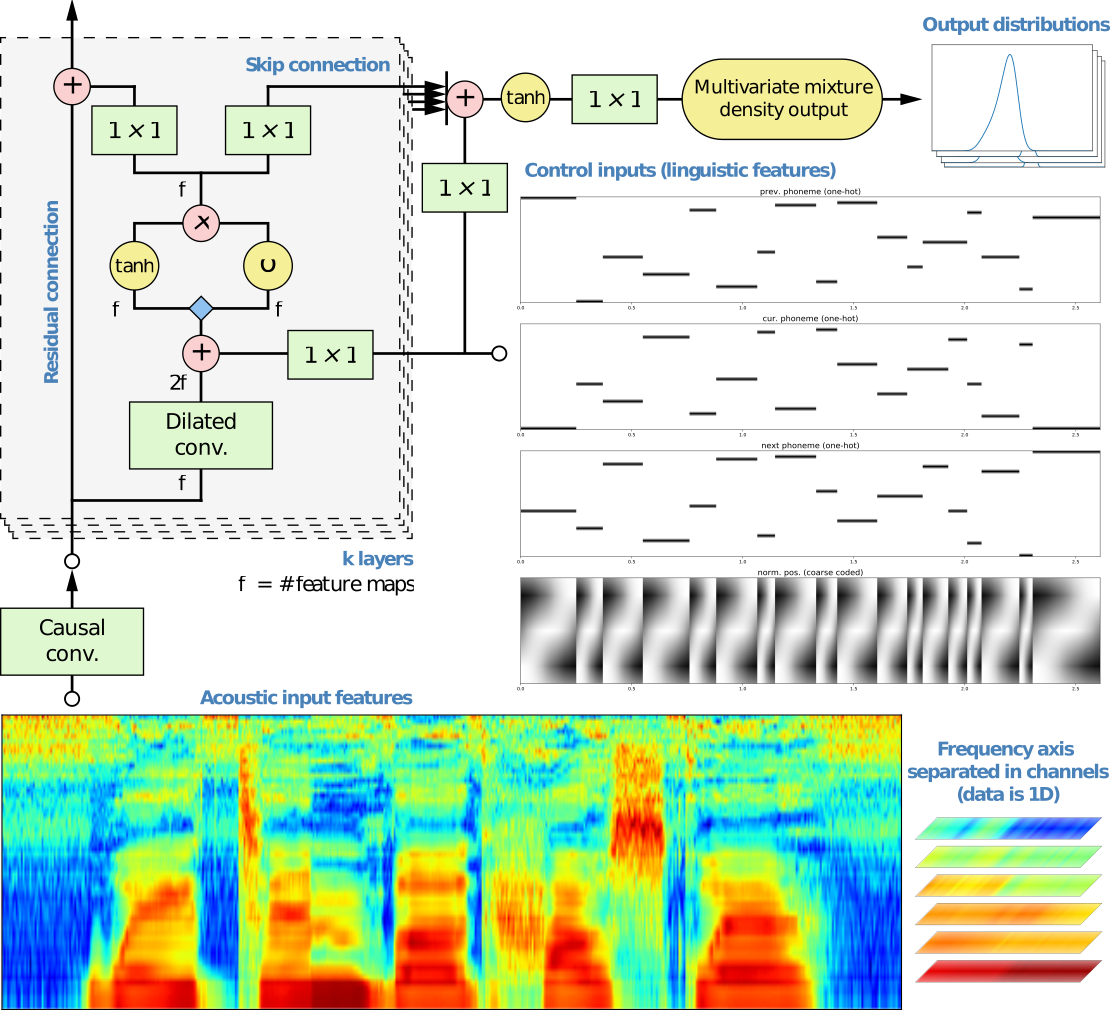
Avances recientes en modelos generativos para síntesis de voz a partir de texto (en inglés, Text-to-Speech Synthesis o TTS) usando redes neuronales profundas using (en inglés, Deep Neural Networks o DNNs), en particular el modelo WaveNet (van den Oord et al., 2016a), han mostrado que aproximaciones basadas en modelos pueden conseguir una calidad de sonido igual o superior a la de sistemas concatenativos. La capacidad de este modelo para generar con precisión formas de onda de habla demuestra claramente que el sobre-suavizado no es un problema. Aunque modelar directamente la señal de la forma de onda es muy interesante, creemos que para la voz cantada la aproximación más tradicional de usar un vocoder paramétrico es más adecuada.
Los resultados son, por lo menos, curiosos.