

Continuando con algo relacionado con la música clásica me encuentro, otra vez en Hacker News, con una noticia de julio en VentureBeat sobre un sistema desarrollado por Florian Henkel, Rainer Kelz y Gerhard Widmer que puede predecir la posición más probable dentro de una partitura correspondiente a una grabación sonora, dando un rendimiento destacadamente superior a los seguidores de partitular más modernos basados en imagen, en términos de precisión de alineamiento
. Para los más interesados, están disponibles tanto el texto académico como el código correspondiente pero el artículo ofrece un resumen de algunos de los puntos clave del proyecto:
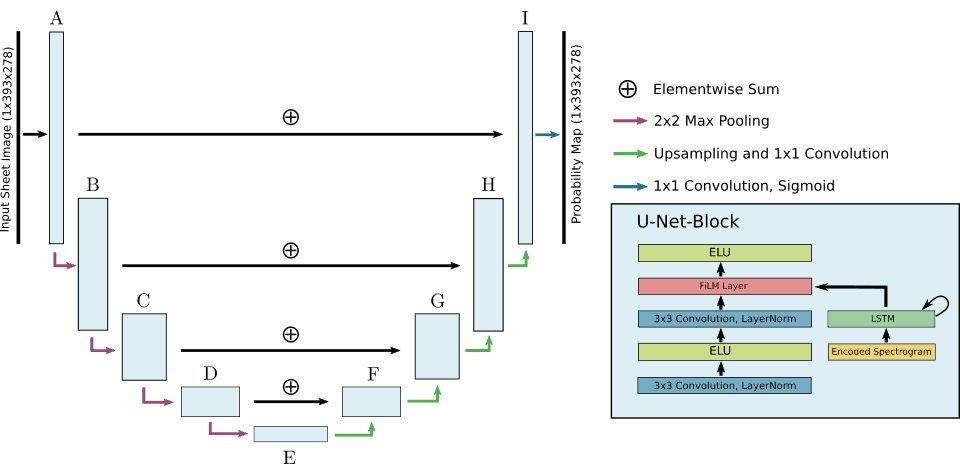
El equipo modelo el seguimiento de la partitura como una tarea de segmentación de imagen. Basándose en una interpretación musical hasta un determinado punto en el tiempo, su sistema predice una máscara de segmentación —una pequeña «pieza» de imagen— para la partitura que se corresponde con la música que está siendo reproducida en ese momento. Mientras que los sistemas de seguimiento que se apoyan sólo en entrada de audio de tamaño fijo no son capaces de distinguir notas repetidas si exceden un determinado contexto, el sistema propuesto no tiene problemas en partituras que aabarcan periodos de tiempo más largos en el audio, según declaran los investigadores.
En el transcurso de los experimentos, los investigadores obtuvieron muestras polifónicas de piano del Multi-model Sheet Music Dataset (MSMD), que abarca temas de varios compositores incluyendo Bach, Mozart y Beethoven. Tras identificar y corregir manualmente los errores de alineamiento, entrenaron su sistema con 353 pares de partituras e información MIDI.
Sin apenas tiempo de indagar en el emuladores WaveNet de equipo de guitarra, voy a tener que poner orden y establecer prioridades entre todas las cosas que quiero curiosear.



