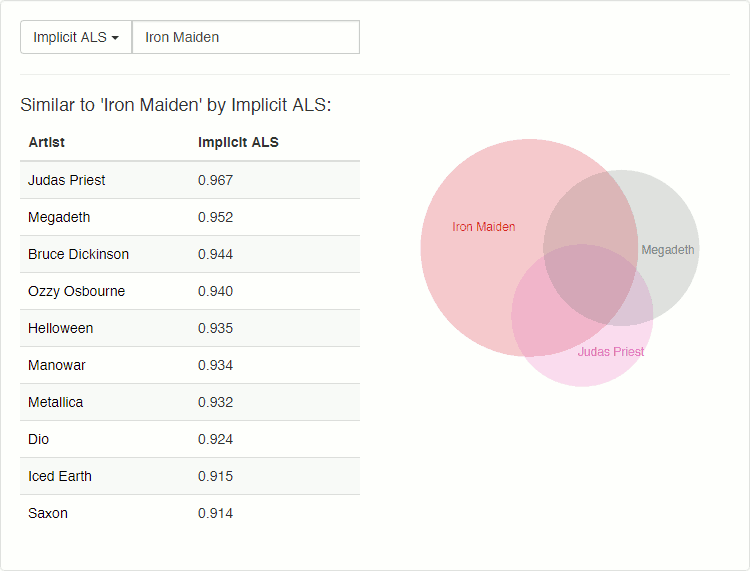
Ben Frederickson, un desarrollador de software que vive en Vancouver, ha publicado un par de entradas en su blog sobre cómo calcular la similitud entre dos artistas en términos de distancia. Para ello hace uso de un conjunto de datos sacados de last.fm en 2008 para plantear y desarrollar distintos métodos.
En la primera entrada parte de un criterio de similitud sencillo: el número de usuarios que dos artistas tienen en común. Rápidamente identifica como problema que los grupos más populares los tendrán casi todos los usuarios, con lo que la métrica no resulta especialmente fiable. La solución más sencilla que propone es calcular el coeficiente de Jaccard, aunque también menciona el coeficiente de Sørensen–Dice y el coeficiente de Ochiai. Después explica cómo tratar el problema como uno geométrico, con sus beneficios y penalizaciones, para pasar a comentar y mostrar las ventajas de usar TF-IDF y, finalmente, Okapi BM25.
Donald Knuth publicó en 1977 “The Complexity of Songs” en la que postula que nuestros ancestros inventaron el concepto de estribillo para reducir la complejidad de las canciones, algo crucial cuando se tienen que memorizar un gran número de ellas. El Primer Lema de Knuth demuestra que si una canción de longitud N entonces el estribillo reduce la complejidad de la canción a cN, donde el factor c < 1.
Knuth demuestra además una forma de producir canciones de complejidad — en notación de Landau — O(√N), un método mejorado por un granjero escocés llamado O. MacDonald. Métodos más ingeniosos producen canciones de complejidad O(log N), una clase conocida como m botellas de cerveza en el muro.
Finalmente, durante el siglo XX — estimulado por el hecho de que el advenimiento de drogas modernas ha llevado a requisitos de aún menos memoria — lleva a la mejora definitiva: canciones arbitrariamente largas con complejidad O(1), por ejemplo, para una canción definida por la relación de recurrencia:
S0=ε, Sk = VkSk-1, k ≥ 1, Vk = ‘That’s the way,’ U ‘I like it,’U, ∀ k ≥ 1 U = ‘uh huh,’ ‘uh huh’
El texto completo se puede leer en este enlace y, aunque se trata de un chiste, como en muchas cosas en la vida, nos reímos porque es gracioso y nos reímos porque es verdad, que diría De Niro haciendo de Capone.
El mes pasado me topé con “Beat Detection Algorithms”, un texto en dos partes (1 y 2) sobre la implementación en Scala de un par de algoritmos sencillos con el objetivo titular. Aparte de la explicación de la teoría tras estas implementaciones se puede encontrar el resultado integrado en el código fuente de un proyecto del autor.
Recuerdo haber echado un ojo a este tipo de análisis matemático (aunque sin llegar a aplicarlo) a finales de la década de los 90, en la estela de la demoscene y con el ascenso de WinAmp y sus complementos de visualización. Remontándome sólo al año pasado, tenía apuntado un artículo sobre detección de pulsaciones usando Web Audio, encontrado a través de EchoJS, nuevamente sin llevarlo a la práctica por mi parte.
Grimes – Go: Peaks with a lowpass, highpass, and bandpass filter, respectively.
Este último enlace lo tenía apuntado junto con otra reseña en EchoJS de un proyecto denominado WaveGL, cuyo objetivo era «generar audio en la GPU y transmitirlo a la tarjeta de audio» y del que señalaban uno de varios ejemplos. Con tantos proyectos de programación que he visto recientemente no estaría mal sacar un poco de tiempo para programar por gusto en lugar de por compromiso.
El otro día leía en Gizmodo que la música digital no existiría sin la transformada de Fourier. Mi neurona no tiene capacidad para recordar muchas cosas, aunque mi sinapsis se dispara de vez en cuando con términos como FFT o fórmulas como esta:
El artículo mencionado es muy breve y superficial, repasando el origen y el significado de la ecuación anterior y señalando en particular la relevancia de esta herramienta matemática para cosas tan cotidianas como la compresión JPEG y MP3. En concreto, comentan que en el proceso de compresión MP3 se utiliza un rango de frecuencias acotado. Eso me recordó a otro texto que había leído en algún momento, y pude volver a localizar, sobre los sonidos que se pierden al comprimir a MP3. En él se señala el proyecto The Ghost in the MP3, cuyo resultado es un vídeo titulado moDernisT [02m35s]:
«moDernisT» fue creado rescatando los sonidos e imágenes perdidos por compresión usando los códecs MP3 y MP4. El sonido está compuesto de material perdido por la compresión mp3 de la canción [de Suzanne Vega] «Tom’s Diner», famosamente usada como uno de los controles principales de las pruebas de escucha en el desarrollo del algoritmo de codificación MP3. Aquí encontramos la forma de la canción intacta pero los detalles son sólo retazos de la original. El vídeo es el fantasma MP4 del correspondiente vídeo creado en colaboración con Takahiro Suzuki. Así, tanto audio como vídeo son los «fantasmas» de sus respetivos códecs de compresión.
La página del proyecto tiene mucha más información y ejemplos facilitados por el responsable del mismo, para los que tengan curiosidad. Leyendo este tipo de cosas a veces pienso que no me importaría repasar alguna de las cosas que estudié en su momento. O aprender cosas nuevas, como lo que señalaba hace unos días de programar música. Luego recuerdo que me faltan cerebro y tiempo para estas cosas y lo procrastino indefinidamente como un campeón.
Antes de nada, debo decir que probablemente no dispongo de los conocimientos matemáticos, violeros y músicales para ofrecer una opinión sólida en estos campos, ni por separado ni en conjunto. Lo que no quiere decir que acepte cualquier otra sin cuestionarla.
Tras ver el vídeo de «1.618» de Allagaeon me dio por hacer una búsqueda somera sobre la «aplicación» de φ en el ámbito sonoro. Aunque parece que hay instancias donde ser observa el famoso 1’618 en el mundo de la acústica y de la construcción de instrumentos no he mucha visto evidencia contrastable de la intencionalidad de estas ocurrencias o su efecto.
Es el caso de los instrumentos Stradivarius. Aparentemente, existe la creencia que el diseño de estos instrumentos sigue la proporción marcada por la razón extrema y media. Esta opinión puede haberse popularizado al figurar en la novela de ficción «El código Da Vinci» de Dan Brown, libro que no he leído —añadiendo quizás desconocimiento literario a mi lista de carencias— y cuya base histórica no me resulta especialmente familiar —Historia, también insuficiente. Con todo, a la vista del enlace anterior, da la impresión que no soy el único en tener dificultades con este planteamiento.
Por un lado, parece que no hay pruebas históricas que apoyen esta teoría, aunque tampoco sé si el autor lo defendería como componente de la parte ficticia de su obra.
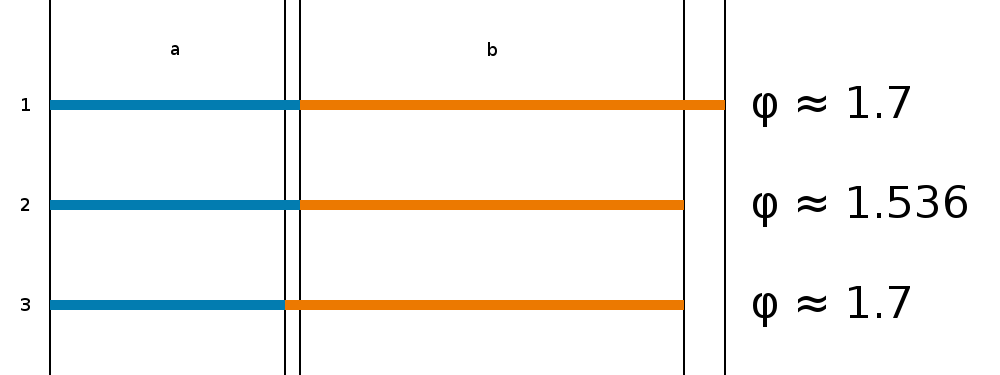
Por otro lado, me gustaría saber cómo de precisa es esta observación y qué tolerancia se puede considerar razonable en las mediciones. Por ejemplo, la siguiente figura sale de este trabajo de Robert van Gend:
Si se toma la imagen anterior (o la original sacada de aquí, o la que se ve en la Wikipedia) y se intenta medir de forma consistente las distancias etiquetadas se pueden observar desviaciones. Importando el PDF del trabajo con GIMP, a 150ppp, y midiendo al pixel las separaciones etiquetadas como a2 y a1 obtengo una relación próxima a 1’69 mientras que entre b2 y b1 es 1’6.
Siendo un número irracional, se pueden aceptar aproximaciones a φ pero entiendo que en todo análisis se partirá de una precisión determinada y una tolerancia. Si cualquiera de esos dos criterios se relaja lo suficiente no resulta tan complicado «ver» la proporción áurea, como en el caso anterior: partiendo de tres cifras decimales (1’618) y un margen de poco más del 5% se obtienen valores de 1’536 a 1’7. Incluso a tamaños pequeños la diferencia es evidente:
Sin descontar el hecho de que los segmentos medidos tienen delimitadores cuestionables. Puedo entender considerar el tamaño del cuerpo respecto al resto del instrumento, o la longitud del mango, entre el clavijero y el cuerpo, a pesar de lo imprecisas que pueden ser las posiciones consideradas. Sin embargo, las referencias tomadas en la escotadura me parecen demasiado arbitrarias. Quien quiera ver más de cerca un Stradivarius y valorar su diseño puede encontrar uno en el Palacio Real de Madrid.
Por último, estaría bien poder cuantificar el efecto real de este principio de diseño en la acústica del instrumento o, ya puestos, en cualquiera de los casos en los que se supone que se está aplicando. En este articulo de Gary Meisner se ensalzan las virtudes de «aplicar» φ en cosas tan dispares como la distribución del espacio en un estudio de grabación o el cableado en altavoces, sin ofrecer más conclusiones que opiniones y valoraciones subjetivas, a veces sólo de los propios fabricantes del producto.






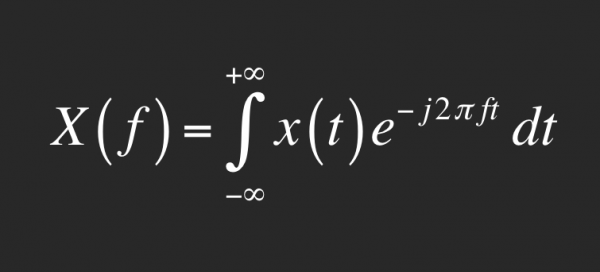



{kind=link}
{kind=link}