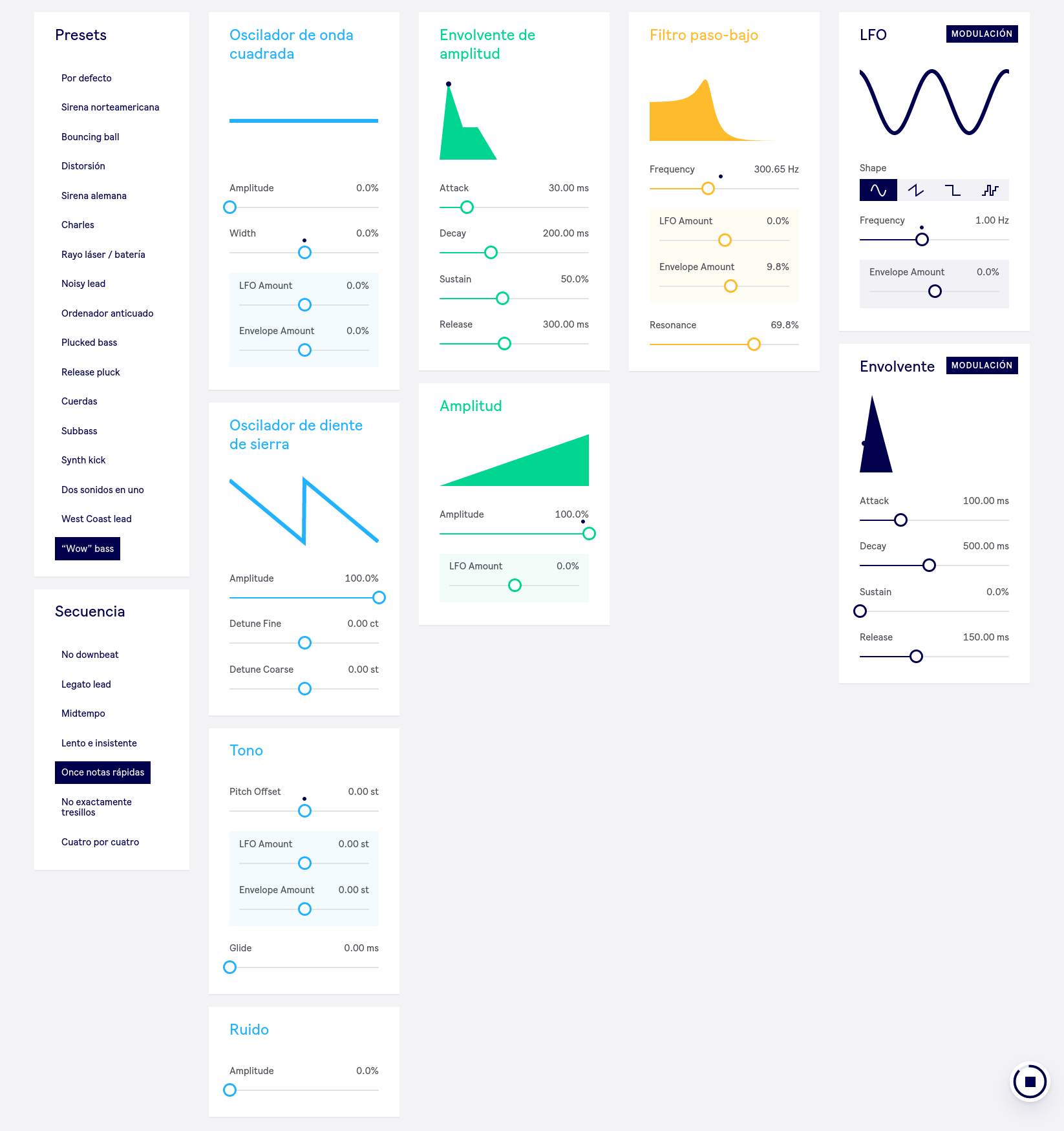
Captura de la interfaz de learningsynths.ableton.com.
Curioseando en el código de la página parece que tira de three.js, tone.js, lodash, algunos componentes de node.js para el navegador y react, aunque no he llegado a ver bien cómo está montado todo. Me ha pasado igual que con el sintetizador multi-toque que veía hace unos años: sin una vista clara del código fuente y/o una explicación del autor tendría que ponerme a diseccionar cómo funciona, y me falta tiempo para dedicarle a esta clase de distracciones.
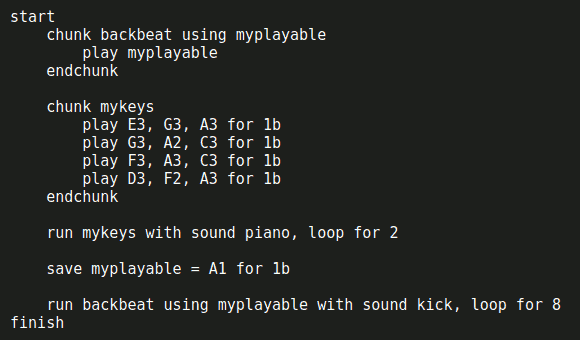
Estaría bien volver a programar algo por gusto, no por compromiso profesional. La última vez que dediqué algo de tiempo a algún entretenimiento personal fue el generador de mapas de calor para cordófonos que mencionaba, y de eso hace prácticamente tres años. Me volvió esta tentación cuando me encontré el otro día en Hacker News con Handel, un pequeño lenguage de programación procedural para escribir canciones en el navegador.
Ejemplo de código de Handel.
Más que las posibilidades como lenguaje de programación/composición, lo que me resulta más interesante aún es poder echar un vistazo al código en GitHub. Claro que si tuviera tiempo para programar por gusto en relación con temas musicales, quizás le echaría antes un ojo a SuperCollider e intentar replicar algún ejercicio simple.
No he hincado el diente a SuperCollider como dije que me gustaría, en parte porque la lista de cosas que me gustaría hacer crece pero mi tiempo disponible es el mismo. Bueno, realmente es menos cada vez pero me refiero a tiempo disponible a lo largo de un día.
Como suele ser habitual en la pila de cosas que llaman mi atención para las que no tengo tiempo, me topo en Hacker News con pippi:
Pippi is a library of computer music modules for python.
It includes a few handy data structures for music like SoundBuffer & Wavetable, which are operator-overloaded to make working with sounds and control structures simpler.
It also includes a lot of useful methods for doing common and not-so-common transformations to sounds and control structures.
It comes with several oscs[… and] many built-in effects and transformations[…, as] well as support for pitch and harmony transformations and non-standard tuning systems[… and] basic graphing functionality[… as] well as other neat stuff like soundfont rendering support via tinysf!
(Normalmente suelo traducir estos párrafos pero hoy estoy algo apurado y sólo me da tiempo a hacer un corta-pega.)
El proyecto parece interesante en sí mismo pero me llamó la atención otro proyecto del mismo autor que extiende el anterior para programar música en directo, Astrid for pippi:
Astrid is an interactive workstation and performance interface for pippi (a DAW & an instrument)
In development! At the moment I’m still just dogfooding this as alpha software, but it should install and run fine in a normal linux audio environment with JACK.
Para los interesados en la idea de programar música de manera interactiva, he visto que algunas personas mencionan Sonic Pi aunque es otro proyecto más que no he probado. Está disponible para Linux, Mac, RasPi y Windows, lo que me hace recordar que en algún momento tengo que probar a replicar de forma casera el procesador de efectos para guitarra hecho con Guitarix sobre una RasPi.
La Piano Phase de Steve Reich (concretamente, el primer movimiento[…]) en un trabajo pionero del Minimalismo temprano. Reicho la compuso a partir de sólo cinco tonos arreglados en un patrón de doce notes y tocando en dos instrumentos. Esto demuestra en que se puede convertir una cantidad mínima de material musical cuando se manipula con el sistema adecuado […]. Utilizando el lenguage de programación musical SuperCollider, he explorado los métodos requeridos para construir este sistema y manipular el proceso programáticamente.
Primer motivo de «Piano Phase» de Steve Reich: 12 semicorcheas agrupadas 4×3. Autor: Sylenius. Fuente: Wikimedia Commons.
Unos meses atrás vi, también en Hacker News, una mención a SuperCollider y la dejé anotada, pero no he llegado a echarle un vistazo como era mi intención. Si me organizara mejor podría dedicar algo de tiempo a hacer el mismo ejercicio de Ezra LaFleur aunque, habiendo visto una «solución», es probable que aprenda menos que si lo hubiera intentando sin marco de referencia. Quizás debiera retarme a algo diferente, como intentar generar alguna pieza de música imposible, aunque me gustaría estar más cómodo con mis capacidades musicales para abordar algo así.
En resumen: es un secuenciador que está diseñado para funcionar un poco como el vídeo de Michel Gondry Star Guitar []
Está hecho con norns, un dispositivo fabricado por monome, cuyos instrumentos están hechos con Lua y SuperCollider.
Pantalla de planetary en funcionamiento. Fuente: Infovore.
Es una de esas cosas que vi en Hacker News y apunté «para más tarde», lo que ha acabado traduciéndose en varios meses de retraso en mi intención original de echarle un ojo.
Puedo entender la fascinación del creador de este secuenciador. Los vídeos de Michel Gondry que señalaba hace más de una década siguen teniendo un efecto casi hipnótico en mí. Lo que me gustaría compartir también con Tom Armitage es la capacidad para desarrollar este tipo de ideas en una tarde.









{kind=link}