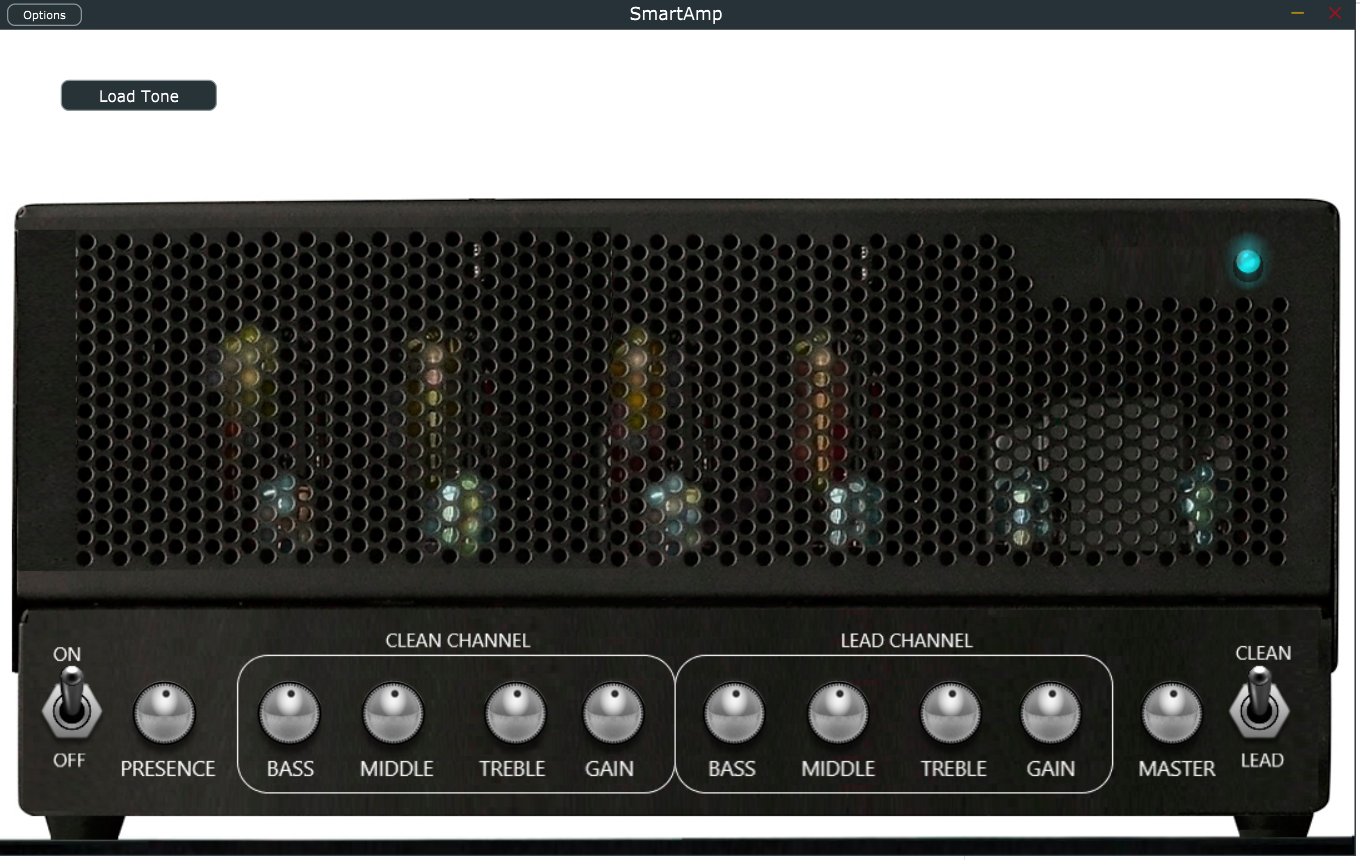
Unos meses atrás le echaba un ojo a un proyecto recreación de un modelo de emulación de amplificadores de guitarra en tiempo real usando aprendizaje automático y ahora me topo en Hacker News con un par de proyectos que también usan aprendizaje automático para recrear sonido de equipo musical. En concreto, lo que veía apuntado era un enlace a SmartGuitarAmp en GitHub:
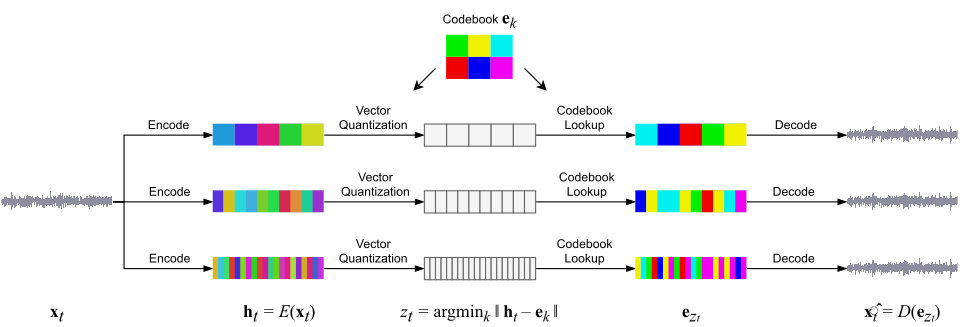
Plugin de guitarra hecho con JUCE que utiliza […] un modelo WaveNet para recrear el sonido de de hardware real. La versión actual modela un amplificador de válvulas pequeño, con la capacidad de añadir más opciones en un futuro. Hay un canal limpio/distorsionado, que es equivalente a las configuraciones limpia y de saturación máxima del amplificador. Los controles de ganancia y EQ se añadieron para modular el sonido modelado.
El mismo desarrollador señala otro software complementario, SmartGuitarPedal, también en GitHub, que tiene una finalidad similar pero enfocada a la emulación de pedales como el TS9 Tubescreamer o el Blues Jr. Se utilizan ganancia y nivel como formas sencillas de controlar el sonido. El modelo WaveNet es efectivo en la emulación de efectos de tipo distorsión o amplificadores de tubo.

Hay un par de demostraciones en el canal de YouTube de GuitarML, para los que tengan curiosidad. Cada vez que menciono WaveNet me quedo con las ganas de profundizar más en el tema. Debe resultar muy interesante.