Me gustaría que se me dieran mejor las matemáticas. Cuando me topo con algún artículo científico o estudio y es de corte empírico, como el de la acústica de Notre-Dame antes y después del fuego de 2019, normalmente soy capaz de seguir el ritmo del texto con mayor o menor comodidad. Sin embargo, cuando el contenido es puramente teórico empiezo a sufrir, aunque debo ser masoca porque no por ello tiene por qué dejar de interesarme.
Es lo que me pasa con «Can one hear the shape of a drum?», un texto de Mark Kac publicado en The American Mathematical Monthly en 1966 (vol. 73, Part II, pp. 1-23) que recibió el premio Lester R. Ford Award (ahora conocido como premio Paul R. Halmos – Lester R. Ford) de la MAA en 1967 y el premio Chauvenet, de la misma institución, en 1968. Lo vi hace unas horas en Hacker News y debo confesar que apenas he pasado de las primeras páginas. Como el propio autor expone, el punto focal de su exposición es la siguiente:
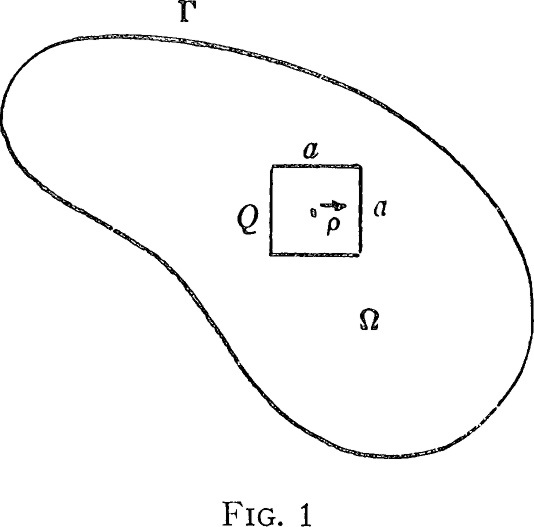
Sean Ω1 y Ω2 dos regiones planares delimitadas por las curvas Γ1 y Γ2, respectivamente, y considérense los problemas de autovalor:
con ½∇2U + λU = 0 en Ω1 con U = 0 en Γ1
con ½∇2V + μV = 0 en Ω2 con V = 0 en Γ2
Asúmase que para cada n, el autovalor λn para Ω1 es igual al autovalor μn para Ω2. Pregunta: ¿Son las regiones Ω1 y Ω2 congruentes en el sentido de la geometría euclídea?
El interrogante anterior comienza la tercera página de un texto de veintitres y, aparentemente, se puede interpretar como, ¿podrías averiguar la forma de un tambor si tuvieras oído absoluto?
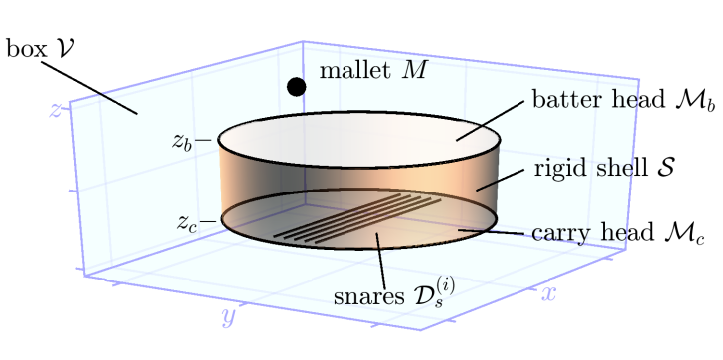
Por lo que cuentan en la Wikipedia, a principios de los noventa Gordon, Webb y Wolpert establecieron que las frecuencias a las que puede vibrar una membrana no determinan su forma. Eso me ha recordado a un proyecto de síntesis de sonido a partir del modelado físico de instrumentos de percusión que tampoco estaría mal re-visitar en profundidad.